k3s 监控方案调研
现阶段容器化方案
容器化监控的曾经出现过的几种方案:
- Heapster + ElasticSearch + Kibana
- Heapster + influxdb + grafana
- Heapster 通过 cAdvisor 组件收集 Node 和 容器的监控数据。kubernetes 1.13 彻底移除对 Heapster 的使用,Heapster 仓库也归档,不再更新维护。
- 基于 Prometheus 生态的监控方案;
Prometheus 在 2016 加入 CNCF ( Cloud Native Computing Foundation )。目前,业界容器化监控 Prometheus 已成为标准和首选。
基于 Prometheus,主要有以下两套部署方案:
- 1、在集群中手动部署 Prometheus 的各种组件,需要部署的组件大致如下:
- 采集组件:
- node-exporter 采集 node 监控
- cAdvisor 容器级别的监控指标
- kube-state-metrics 采集 pod 相关监控指标
- 持久化存储组件:
- 临时 prometheus
- 持久化 influxdb /VictorMetric
- 报警组件:
- alermanager
- n9e,v5版本 已全面改版支持 Promtheus和VictoriaMetric作为存储,完全可以单独作为报警组件使用。
- 采集组件:
手动部署可参考文档:https://docs.prometheus.cool/Kubernetes/Prometheus-Statefulsets-1/
- 2、使用kube-prometheus,基于 CoreOS 组织之前发布的 Prometheus Operator 来实现部署维护;
该存储库收集了 Kubernetes 清单、Grafana 仪表板和 Prometheus 规则以及文档和脚本,以使用 Prometheus Operator 提供易于操作的端到端 Kubernetes 集群监控与 Prometheus。
- k8s 官方 Operator 文档:https://kubernetes.io/zh/docs/concepts/extend-kubernetes/operator/
- Operator Hub 文档:https://operatorhub.io/
- Prometheus Operator 文档:https://prometheus-operator.dev/
- 3、使用 helm 安装 ,
https://prometheus-community.github.io/helm-charts https://www.infoq.cn/article/uj12knworcwg0kke8zfv
Prometheus 方案详解
数据采集项
日常监控的采集项:
- 基础设施,cpu/mem/disk/net
- 业务信息,port/process/trace/link
- 自定义,特有指标。
容器需要采集或监控的数据指标:
- 基础设施,服务器节点(node 节点)健康情况
- k8s 基础组件健康情况
- k8s 整体资源的饱和度
- 自定义。
各指标对应采集方案和组件如下:
- 基础设置
- node 主机信息 ---> node-exporter
- 各组件监控及资源使用情况、容器性能(如容器的 CPU、内存、文件和网络的使用情况),cAdvisor ---> state-metrics
- 业务信息:
- 容器健康状态,Probes ---> state-metrics
- 健康探测(link/trace)---> 外部探测(自建、阿里云)
- 自定义,---> 自己暴露 metrics 接口
数据存储
Prometheus 作为收集和临时存储使用,因为单点不具备扩容能力,不适合做持久化存储。
持久化存储,目前业界有三种种比较成熟的开源方案:
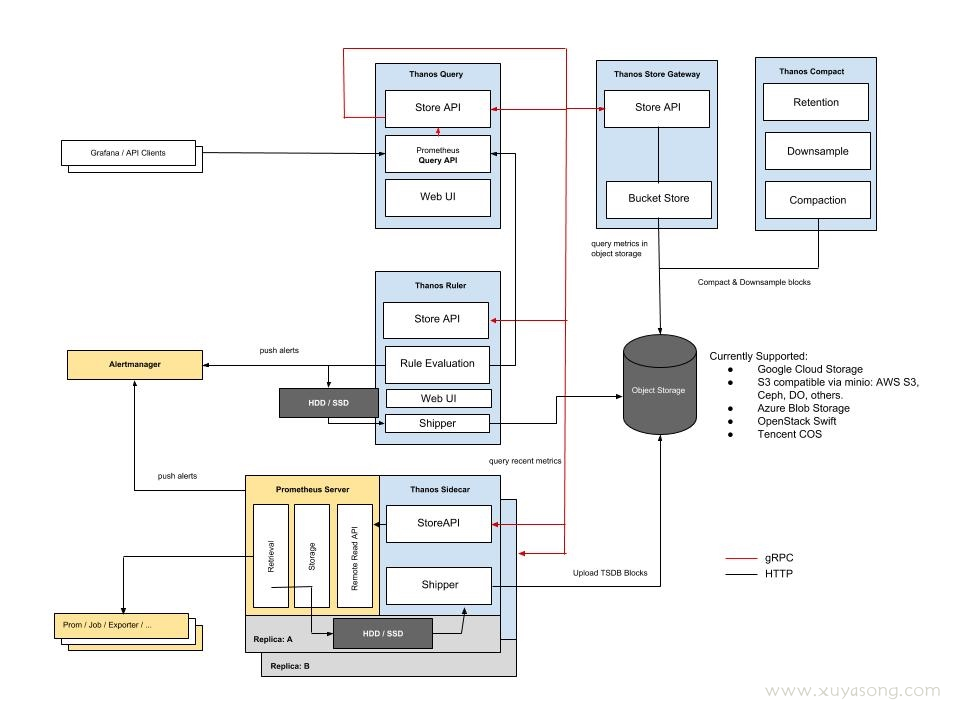
- Thanos 架构
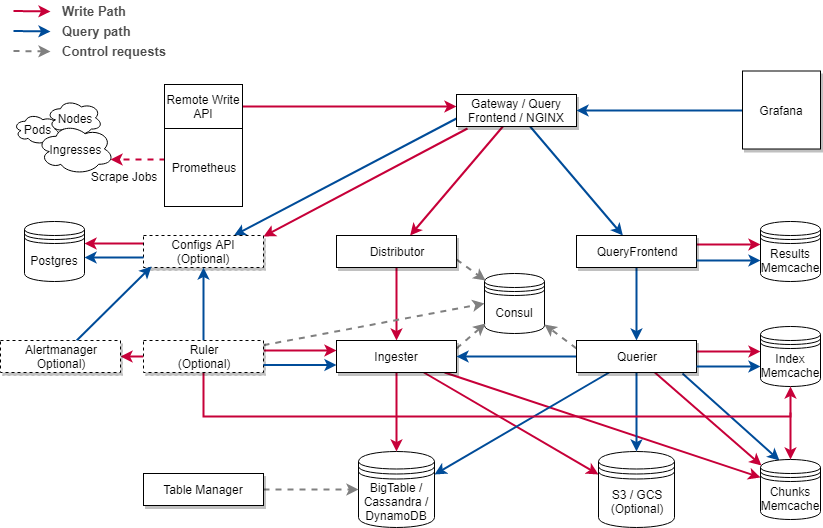
- Cortex 架构
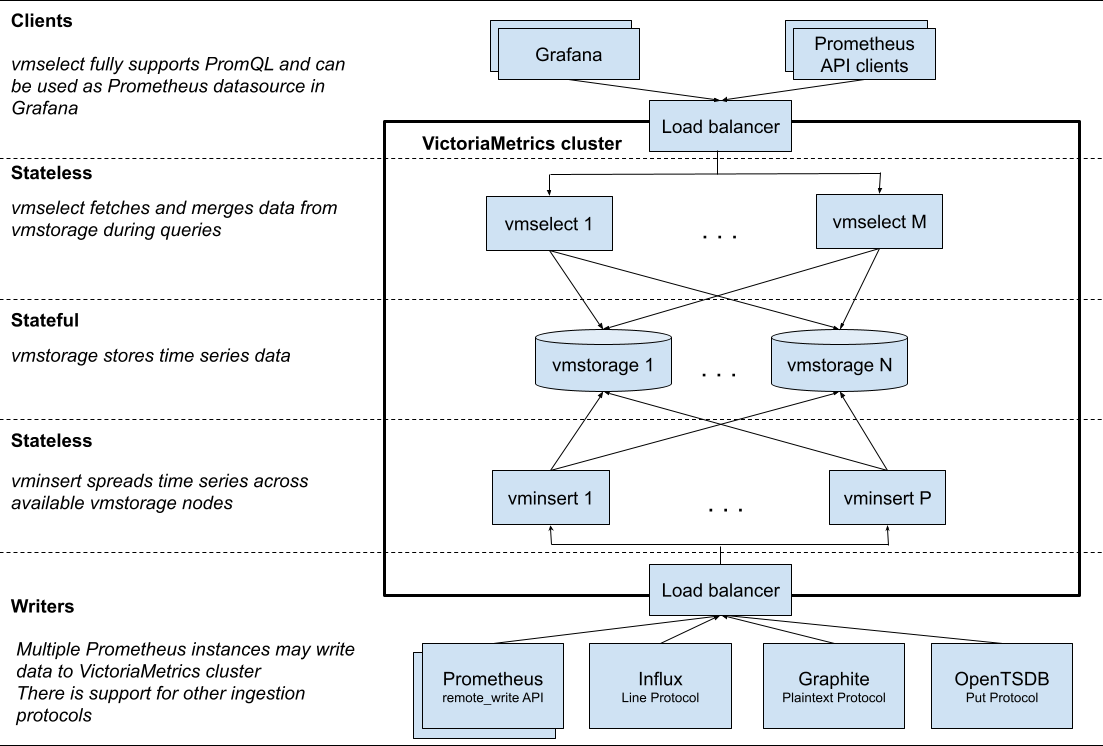
- VictoriaMetric (只支持写,不支持读) 架构
Thanos vs VictoriaMetric 两种方案对比,可参考文档:
https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-thanos
Cortex vs VictoriaMetric 对比:
- https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-cortex
总结下三种方案对比大致如下:
架构上:vm 组件少,架构简单,不依赖第三方组件。Thanos 最少可部署三个基础组件 Sidecar、Store Gateway、Query,需要外部对象存储。Cortex 基础组件:Nginx/gateway、Distributor、Ingester、Query,依赖第三方组件如 Consul、Memcache 等。
数据高可用上:vm 通过 Prometheus RemoteApi 实时推送数据,只可能会丢失几秒钟的数据,Prometheus v2.8.0+ 会从 WAL 中同步数据,理论上不会丢失数据。 vm 和 cortex 都支持副本,保证集群节点有问题时,数据的可用性。Thanos 数据存储在对象存储,依赖对象存储的高可用性。
功能兼容性丰富度:都兼容 Prometheus PromQL / 多租户等。除了 Prometheus remote_write 协议之外,还接受多种流行数据摄取协议中的数据 - InfluxDB、OpenTSDB、Graphite、CSV、JSON、本机二进制文件。
性能:vm 查询走本地磁盘相对高效,vmselect 聚合多节点副本,实现去重。Cortex 经过其他大厂生产验证性能略逊于 vm, 参考这里。Thanos 查询短时间的数据时,性能高,因为数据在 Prometheus 实例上,查询长时间的数据时,因为数据块在对象存储,受网络环境影响比较大。
报警方案
alertmanager 技术栈方案;
n9e v5.3.0 支持了openfalcon数据结构的上报,这样使用老openfalcon作为监控的平台,就可以把数据汇报给n9e 存储到prometheus,统一做监控报警。
与现有监控结合
n9e 提供了基于PromQL 方式数据源的即使和自定义dashboard 功能,且支持多集群。
grafana
- 有默认值,可从 template 中查看。自定义修改认证方式可参考这里;
- 直接修改 helm 配置 values 文件,可对 grafana 做一些定制化的部署;
部署高可用
多 Prometheus 副本,接后端 VictoriaMetric 聚合去重查询。