Ceph-deplpy 部署 nautilus
ceph 简介
架构
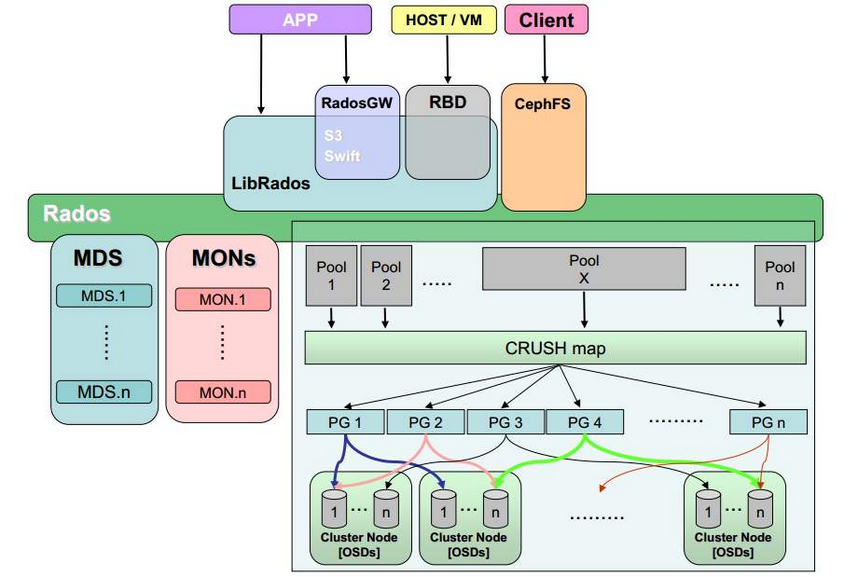
ceph 三种接口
ceph支持的三种存储接口:
- Object对象存储:有原生的API,而且也兼容 Swift 和 S3 的 API;
- Block块存储:支持精简配置、快照、克隆;
- File文件:Posix 接口,支持快照;
ceph 核心组件和作用
- Ceph OSD: Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
- Monitor: Ceph的Monitor守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map、PG(Placement Group) map、CRUSH map。 这些映射是Ceph守护进程之间相互协调的关键簇状态。 监视器还负责管理守护进程和客户端之间的身份验证。 通常需要至少三个监视器来实现冗余和高可用性。
- Managers: Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
- MDS: Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力
其他概念:
pool 存储池 存储池是用于存储对象的逻辑组。如果您先部署集群而不创建存储池,Ceph 会使用默认存储池来存储数据。我们在创建pool存储池时需要指定pg的个数,来创建pg,pg个数不建议轻易改动,会影响集群:
- 过小,会影响数据的均匀分布
- 过大,会影响资源消耗,清理时间(以pg为单位),数据持久性(osd会属于过多pg,故障时压力大)
placement group pg 组(归置组)逻辑概念,是ceph中分配数据的最小存储单位,用于跨 OSD 将数据存储在某个存储池中的内部数据结构。CRUSH 索引中定义了 Ceph 将数据存储到 PG 中的方式。创建存储池时,您可以为其设置归置组数量。典型配置为每个 OSD 使用约 100 个归置组,以提供最佳平衡而又不会耗费太多计算资源。一个pg内包含多个osd daemon,多对多,一个osd可以属于多个pg组。
CRUSH 规则:在存储池中存储数据时,系统会根据映射到该存储池的 CRUSH 规则集来放置对象及其副本或块(如果是纠删码存储池)。您可为存储池创建自定义 CRUSH 规则。
快照:使用 ceph osd pool mksnap 创建快照时,可高效创建特定存储池的快照。
pg组与osd daemon之间的关系为多对多关系。
官方建议 : 如果ceph集群很长一段时间都不会拓展,一个osd deamon属于100个pg组。否则,一个osd deamon属于200个pg组。
object ---> pg组 是通过hash算法实现的
pg组 ---> osd daemon 是通过crush算法实现的ceph 四种使用场景
- LIBRADOS应用: 通俗的说,Librados提供了应用程序对RADOS的直接访问,目前Librados已经提供了对C、C++、Java、Python、Ruby和PHP的支持。它支持单个单项的原子操作,如同时更新数据和属性、CAS操作,同时有对象粒度的快照操作。它的实现是基于RADOS的插件API,也就是在RADOS上运行的封装库。
- RADOSGW应用: 这类应用基于Librados之上,增加了HTTP协议,提供RESTful接口并且兼容S3、Swfit接口。RADOSGW将Ceph集群作为分布式对象存储,对外提供服务。
- RBD应用: 这类应用也是基于Librados之上的,细分为下面两种应用场景。
- 第一种应用场景为虚拟机提供块设备。通过Librbd可以创建一个块设备(Container),然后通过QEMU/KVM附加到VM上。通过Container和VM的解耦,使得块设备可以被绑定到不同的VM上。
- 第二种应用场景为主机提供块设备。这种场景是传统意义上的理解的块存储。 以上两种方式都是将一个虚拟的块设备分片存储在RADOS中,都会利用数据条带化提高数据并行传输,都支持块设备的快照、COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。
- CephFS(Ceph文件系统)应用: 这类应用是基于RADOS实现的PB级分布式文件系统,其中引入MDS(Meta Date Server),它主要为兼容POSIX文件系统提供元数据,比如文件目录和文件元数据。同时MDS会将元数据存储在RADOS中,这样元数据本身也达到了并行化,可以大大加快文件操作的速度。MDS本身不为Client提供数据文件,只为Client提供对元数据的操作。当Client打开一个文件时,会查询并更新MDS相应的元数据(如文件包括的对象信息),然后再根据提供的对象信息直接从RADOS中得到文件数据。
部署
环境准备
# 清理 已有的环境配置
ceph-deploy purge ceph01 ceph02 ceph03
ceph-deploy purgedata ceph01 ceph02 ceph03
ceph-deploy forgetkeys
rm ceph.*
# 配置host
10.168.81.218 ceph01
10.168.81.219 ceph02
10.168.81.220 ceph03
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时配置 ntp 时间同步
ntp服务必须配置否则ceph mon 节点会有错误提示。我们按照一个ntp server,其他 agent 来server同步时间配置。当然如果网络条件允许的话,也可以都从外部时钟服务器同步。
其中一个节点配置ntp server
yum install -y ntp
systemctl start ntpd
systemctl enable ntpd
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0 #将当前的 UTC 时间写入硬件时钟
#这样我们的ntp server自动连接到外网,进行同步 (时间同步完成在IP前面会有一个*号)
[root@ceph-01 ~]# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
120.25.115.20 10.137.53.7 2 u 8 64 17 40.203 -24.837 0.253
*203.107.6.88 100.107.25.114 2 u 8 64 17 14.998 -22.611 0.186其他节点可配置 NTP Agent (ntp agent同步ntp server时间),模仿生产机房环境的一个架构。
ntp agent需要修改ntp server的地址
[root@ceph-02 ~]# vim /etc/ntp.conf
server 192.168.31.20 iburst
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#注释默认的server,添加一条我们ntp server的地址
[root@ceph-02 ~]# systemctl restart ntpd
[root@ceph-02 ~]# systemctl enable ntpd
#等待几分钟出现*号代表同步完成
[root@ceph-02 ~]# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
*192.168.31.20 120.25.115.20 3 u 13 64 1 0.125 -19.095 0.095
#ceph-03节点操作相同配置ceph 国内 yum 源
vim /etc/yum.repos.d/ceph.repo 使用阿里源加速下载:
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/$basearch
enabled=1
gpgcheck=0
type=rpm-md
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=0
type=rpm-md
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=0
type=rpm-md初始化集群
1、安装 ceph-deploy 工具
# 安装 ceph-deploy 工具
sudo yum update
sudo yum install ceph-deploy -y
$ mkdir ceph-deploy && cd ceph-deploy2、各节点安装需要的软件包
为了方便使用ceph-deploy工具多节点安装,我们需要打通ssh 免密登录。
# 各节点安装 ceph 需要的 ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds
ceph-deploy install --repo-url=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/ --gpg-url=http://mirrors.aliyun.com/ceph/keys/release.asc ceph01 ceph02 ceph03
# 或
ceph-deploy install --no-adjust-repos ceph-10 ceph-11 ceph-12 # 安装ceph软件包,其中--no-adjust-repos为不使用ceph默认yum源,因之前配置了yum源故不使用默认yum源
# 可能会有依赖的问题,执行下边命令 更新下包
sudo yum -y install epel-release3、初始化集群
# 初始化集群, ceph01 为mon 节点
ceph-deploy new --public-network 10.168.81.0/24 ceph01
# new 初始化集群,生成ceph.conf,ceph.mon.keyring,ceph-deploy-ceph.log 三个文件,其中ceph.conf为配置文件,ceph.mon.keyring密钥文件,ceph-deploy-ceph.log为日志文件
# --public-network:对外网络,用于客户端访问
# --cluster-network:集群内部信息同步网络
# ceph-node-11:将此节点设置为Monitor节点4、初始化 mon 节点
集群初始化后,会生成配置文件和 mon key 等信息,执行的节点自动归为 mon 节点,接下来需要初始化 mon 节点
# 创建其他 mon 节点,mon 节点一般为 集群数/2 + 1 个
ceph-deploy mon create ceph02 ceph03 # 创建其他mon 节点
# 在节点上安装mon进程,因poxos算法,mon服务个数为奇数个
# 初始化 mon 所有节点
ceph-deploy mon create-initial
# 拷贝admin的秘钥文件到节点配置目录 /etc/ceph
ceph-deploy admin ceph01 ceph02 ceph03
# 分发 mon 秘钥到其他mon节点
ceph-deploy gatherkeys ceph-10 ceph-11 ceph-12
# 禁用不安全模式 否则回报:health: HEALTH_WARN mons are allowing insecure global_id reclaim
ceph config set mon auth_allow_insecure_global_id_reclaim false5、 部署 manager 节点
# manager 生产建议最少2个
ceph-deploy mgr create ceph01 ceph026、部署 osd 节点
# 空磁盘可直接创建
ceph-deploy osd create --data /dev/sdb ceph01
ceph-deploy osd create --data /dev/sdb ceph02
ceph-deploy osd create --data /dev/sdb ceph03
# 当有保存时,修复后 可使用参数 --overwrite-conf 重新创建
ceph-deploy --overwrite-conf osd create --data /dev/sdb ceph03
# 非空磁盘,需要清理下
ceph-volume lvm zap --destroy /dev/sd*
# 清理 ceph lvm 分区 和 vg 组
fdisk -l |grep '/dev/mapper/ceph'
lvremove /dev/mapper/ceph--a1e19c3e--178f--46a0--90a1--7cc56ae57e56-osd--block--e3ab1167--8a1e--4b92--8e37--eea10eb2d885
lsblk
vgs
vgremove ceph-a1e19c3e-178f-46a0-90a1-7cc56ae57e56
# 查看 osd
ceph osd tree查看机器默认配置:
ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show7、部署mds 节点
ceph-deploy mds create ceph01 ceph02 ceph03启用存储
对象存储
# 常见 rgw 网关节点 ,会自动创建 pool 和 pg
ceph-deploy rgw create ceph01
# 查看ceph状态
ceph -s
cluster:
id: cd529257-bef0-4244-b0f5-699d0e618faa
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph01,ceph02,ceph03 (age 21h)
mgr: ceph01(active, since 2h), standbys: ceph02
mds: 3 up:standby
osd: 3 osds: 3 up (since 21h), 3 in (since 21h)
rgw: 1 daemon active (ceph01)
task status:
data:
pools: 4 pools, 128 pgs
objects: 30 objects, 1.2 KiB
usage: 3.0 GiB used, 297 GiB / 300 GiB avail
pgs: 128 active+clean
io:
client: 4.4 KiB/s rd, 0 B/s wr, 6 op/s rd, 4 op/s wr
# 查看ceph pool 信息
ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 300 GiB 297 GiB 11 MiB 3.0 GiB 1.00
TOTAL 300 GiB 297 GiB 11 MiB 3.0 GiB 1.00
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.rgw.root 1 32 1.2 KiB 4 768 KiB 0 94 GiB
default.rgw.control 2 32 0 B 8 0 B 0 94 GiB
default.rgw.meta 3 32 0 B 0 0 B 0 94 GiB
default.rgw.log 4 32 0 B 175 0 B 0 94 GiB默认情况下,RGW实例将监听端口7480。这可以通过在运行RGW的节点上编辑ceph.conf来改变,如下所示:
[client]
rgw frontends = civetweb port=80重启服务生效:
systemctl restart ceph-radosgw.service块存储
https://juejin.cn/post/6996864347263729701#heading-29 https://i4t.com/5267.html
文件存储
ceph 节点扩容
增加 mon 节点
# 添加 mon 节点
ceph-deploy mon add ceph02
ceph-deploy mon add ceph03
# 检查仲裁状态
ceph quorum_status --format json-pretty
# 注意,要保证各节点 ntpd 服务启动,否则会报错误: health: HEALTH_WARN clock skew detected on mon.ceph02, mon.ceph03
ceph mon stat # 也可以单独查看monitor状态
ceph mon dump # dump查看monitor状态扩容 mgr 节点
# 增加
ceph-deploy mgr create ceph02 ceph03ceph dashboard
yum install ceph-mgr-dashboard -y
ceph mgr module disable dashboard
ceph mgr module enable dashboard --force
# --force dashborad 只在 mgr 主节点支持 需要添加这个参数,命令在主节点执行,来启用。
# 创建证书
ceph dashboard create-self-signed-cert
# 创建用户名密码
cat >/opt/secretkey<<EOF
123123
EOF
ceph dashboard ac-user-create admin administrator -i /opt/secretkey
# 查看服务
ceph mgr services开启 Object Gateway 管理功能
# 1、创建rgw用户
radosgw-admin user info --uid=user01
# 2、提供Dashboard证书
ceph dashboard set-rgw-api-access-key $access_key
ceph dashboard set-rgw-api-secret-key $secret_key
# 3、配置rgw主机名和端口
ceph dashboard set-rgw-api-host 10.168.81.218
# 4、刷新web页面启用 prometheus
ceph mgr module enable prometheus
netstat -nltp | grep mgr 检查端口
curl 127.0.0.1:9283/metrics 测试返回值命令参考
ceph-deploy new [initial-monitor-node(s)]
开始部署一个集群,生成配置文件、keyring、一个日志文件。
ceph-deploy install [HOST] [HOST…]
在远程主机上安装ceph相关的软件包, –release可以指定版本,默认是firefly。
ceph-deploy mon create-initial
部署初始monitor成员,即配置文件中mon initial members中的monitors。部署直到他们形成表决团,然后搜集keys,并且在这个过程中报告monitor的状态。
ceph-deploy mon create [HOST] [HOST…]
显示的部署monitor,如果create后面不跟参数,则默认是mon initial members里的主机。
ceph-deploy mon add [HOST]
将一个monitor加入到集群之中。
ceph-deploy mon destroy [HOST]
在主机上完全的移除monitor,它会停止了ceph-mon服务,并且检查是否真的停止了,创建一个归档文件夹mon-remove在/var/lib/ceph目录下。
ceph-deploy gatherkeys [HOST] [HOST…]
获取提供新节点的验证keys。这些keys会在新的MON/OSD/MD加入的时候使用。
ceph-deploy disk list [HOST]
列举出远程主机上的磁盘。实际上调用ceph-disk命令来实现功能。
ceph-deploy disk prepare [HOST:[DISK]]
为OSD准备一个目录、磁盘,它会创建一个GPT分区,用ceph的uuid标记这个分区,创建文件系统,标记该文件系统可以被ceph使用。
ceph-deploy disk activate [HOST:[DISK]]
激活准备好的OSD分区。它会mount该分区到一个临时的位置,申请OSD ID,重新mount到正确的位置/var/lib/ceph/osd/ceph-{osd id}, 并且会启动ceph-osd。
ceph-deploy disk zap [HOST:[DISK]]
擦除对应磁盘的分区表和内容。实际上它是调用sgdisk –zap-all来销毁GPT和MBR, 所以磁盘可以被重新分区。
ceph-deploy osd prepare HOST:DISK[:JOURNAL] [HOST:DISK[:JOURNAL]…]
为osd准备一个目录、磁盘。它会检查是否超过MAX PIDs,读取bootstrap-osd的key或者写一个(如果没有找到的话),然后它会使用ceph-disk的prepare命令来准备磁盘、日志,并且把OSD部署到指定的主机上。
ceph-deploy osd active HOST:DISK[:JOURNAL] [HOST:DISK[:JOURNAL]…]
激活上一步的OSD。实际上它会调用ceph-disk的active命令,这个时候OSD会up and in。
ceph-deploy osd create HOST:DISK[:JOURNAL] [HOST:DISK[:JOURNAL]…]
上两个命令的综合。
ceph-deploy osd list HOST:DISK[:JOURNAL] [HOST:DISK[:JOURNAL]…]
列举磁盘分区。
ceph-deploy admin [HOST] [HOST…]
将client.admin的key push到远程主机。将ceph-admin节点下的client.admin keyring push到远程主机/etc/ceph/下面。
ceph-deploy push [HOST] [HOST…]
将ceph-admin下的ceph.conf配置文件push到目标主机下的/etc/ceph/目录。 ceph-deploy pull [HOST]是相反的过程。
ceph-deploy uninstall [HOST] [HOST…]
从远处主机上卸载ceph软件包。有些包是不会删除的,像librbd1, librados2。
ceph-deploy purge [HOST] [HOST…]
类似上一条命令,增加了删除data。
ceph-deploy purgedata [HOST] [HOST…]
删除/var/lib/ceph目录下的数据,它同样也会删除/etc/ceph下的内容。
ceph-deploy forgetkeys
删除本地目录下的所有验证keyring, 包括client.admin, monitor, bootstrap系列。
ceph-deploy pkg –install/–remove [PKGs] [HOST] [HOST…]
在远程主机上安装或者卸载软件包。[PKGs]是逗号分隔的软件包名列表。