Kafka 使用总结
历史
消息代理,狭义的讲它是一种按照某专递协议进行消息传递的架构模式。常用来解决系统之间的耦合、异步任务调用和瞬时流量的应对问题。随着互联网行业的发展,大数据、分布式架构的兴起,消息代理的使用越来越多,高吞吐、实时性的要求越来越高。
Kafka 就是在这样的背景下诞生的。在2010年,Linkedin公司需要将大量的数据集成到现有架构中做处理,当时现有的传消息代理中间件无法满足他们的需求,高吞吐、低延迟且安全容错率高。他们决定自己开发一套消息代理系统,就此Kafka 诞生。次年,他们将它开源到了github,因为它高吞吐、低延迟的特点被纳入apache孵化器项目,2012年成为apache顶级项目。
随着Kafka的发展,它已经不局限于消息代理。现在已发展为一个分布式流处理平台,具有以下三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
kafka的中常用概念
在我们使用Kafka之前,先来了解下期中的一些概念。Kafka的官方文档已经描述的非常详细,下边是一些总结:
常识类
- Kafka作为一个集群,运行在一台或者多台服务器上.
- Kafka 通过 topic 对存储的流数据进行分类。
- 每条记录中包含一个key,一个value和一个timestamp(时间戳)。
- kafka中的消息是无状态的,不会随着消费而消失,只会根据保留策略来释放。
组件类
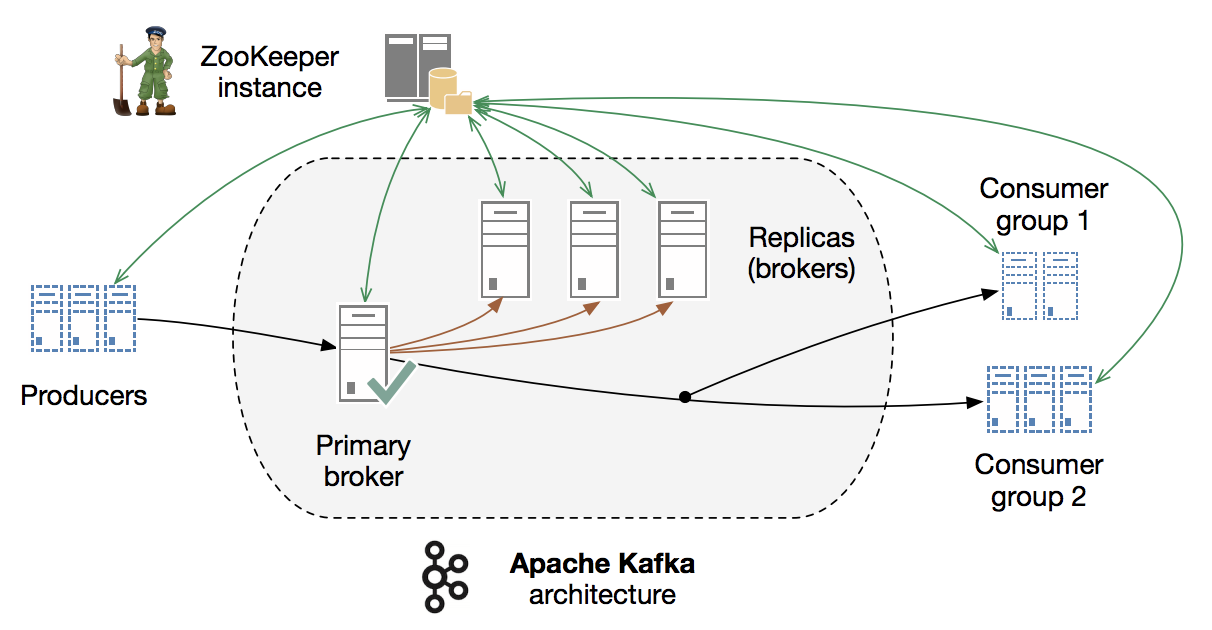
- 主题(topic):一个topic可以认为是一类消息。
- 分区(partition):每个topic可以分为多个分区,存储到集群的不同节点,同时可以设置副本的个数来达到可容错的效果。分区突破主机单文件大小的限制,并且为并行数据处理提供了条件。
- 复制备份(replication):kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有),备份的个数可以通过broker配置文件来设定。
- 生产者(producers):将消息写入到kakfa服务端的称之为生产者。Producers将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition
- 代理(Broker):已发布的消息保存在一组服务节点中,每个节点称之为一个broker,所有的broker组成一个kafka集群。
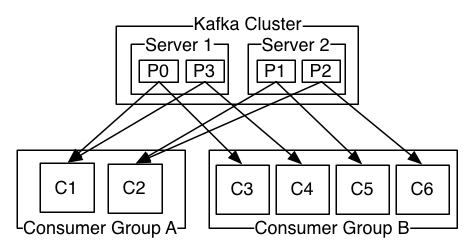
- 消费者(customers):将消息从kakfa服务端取出使用的称之为消费者。如果所有的consumer都具有相同的group,这种情况和队列模式很像,消息将会在consumers之间负载均衡;如果所有的consumer都具有不同的group,那这就是"发布-订阅",消息将会广播给所有的消费者。
- zookeeper: 用来存储机器的配置信息。
Kafka 搭建
Kafka集群的搭建非常简单,可直接参考官方文档。
启动时注意
在Kafka启动时,kafka-server-start.sh 提供了daemon模式,可通过添加参数-daemon 实现。
Kafka启动后,我们需要监控kafka的运行情况,许多开源的监控的系统需要Kafka打开 JMX功能,我们直接指定JMX的端口即可,kafka-server-start.sh中做了处理,它会自动添加其他jvm需要的参数。
总结上边,我们的完整启动命令如下:
JMX_PORT=9988 ./bin/kafka-server-start.sh -daemon config/server.properties几个重要的配置
offsets.topic.replication.factortopic 分区的副本数,默认为1,即没有副本。当有broker宕机的时候,topic信息不全,导致集群不可用。建议设置参数值大于1.log.retention.hours日志文件清理,默认为168。建议根据自己磁盘和数据量合理设置,以免因磁盘满造成宕机不可用。
使用问题和优化
针对kafka的管理监控问题
对于kafka管理及监控,这里推荐两款开源工具 Kafka Manager 和 Kafka Eagle。
Kafka Manager
该工具是目前最后欢迎的Kafka机器管理工具,是有雅虎开源的。提供了简单的web页面,可实现多集群的主题管理和消费者等状态的查看。
Kafka Eagle
该工具是国内同行开发的,支持对Kafka的简单管理和报警,可以看作者这篇剖析来进一步了解:Kafka监控系统Kafka Eagle剖析
利用Customer Group 实现消费者的高可用
根据消费者组(Customer Group)的特性,不同的消费者组可以订阅同样的topic数据。Topic 会将数据广播到每个订阅的消费者组,在消费者组内,一个topic的分区对应一个消费者来消费,每个topic的分区只能被一个消费者消费。
在一个消费者组中,当有消费者宕机时,该消费者消费的分区会重新平衡到其他消费者上继续消费,从消费者组整体来看,仍然是完整可用的。这样以组作为一个消费集群来看,便是高可用的了。