 夜莺 V6 之初体验
夜莺 V6 之初体验
该文为看了秦老板的夜莺黄埔营直播后的一些笔记和思考,分享大家,希望有收获。
# n9e v6 直观感受
在上个月 10 号左右,夜莺团队发布了 V6 版本,将后端的数据源转移到前端可配置,整个产品在可观测性领域更进了一步。有了对标 grafana 的可能性,grafana 在时序数据出图方面,已成为首选,功能性和易用性上 V6 版相较于之前也有很多进步,几乎可以平替 grafana 大部分图表。
我司目前在用的是 V5 版本,V5 后端直接可以对接 Promethues 或者 VM,可以使用 WebUI 来管理 Prometheus 的报警规则。Alertmanager 的 yaml 文件规则有一定的学习成本,而 n9e 完全没有可以说是傻瓜化的,你只要会写 promQL 就可以配置报警规则,业务人员更容易上手。
更多 V6 release note 可参考这里 (opens new window)。
# n9e v6 架构
下边是我做的笔记和思考,分享给大家参考
- 1/ n9e V6 将核心服务(V5 版本的 webapi、server)都集成到了一个二进制文件,部署更加的简单;
这是一个中心汇集的部署架构,相较之前 webapi server的架构更简单,只有一套配置文件,在做部署的时候更加方便。
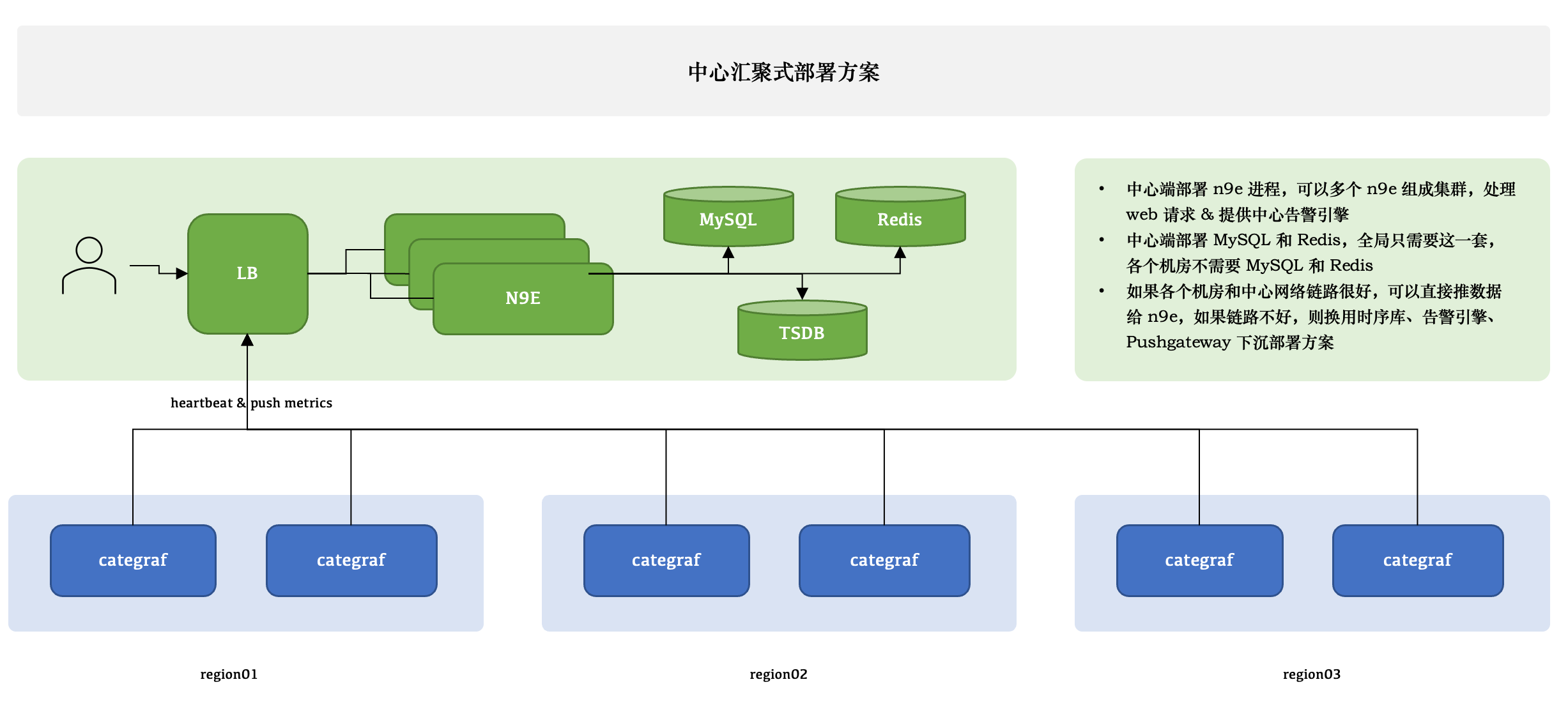
- 2/ V6 当机房网络和 n9e 集群链接不通畅或有限制时,可使用 nginx 代理。
我司在多机房部署时,便使用了 nginx 作为网关代理,有些公司机房的机器并不是都可以出公网的,这种时候也可以使用 nginx 代理,机房机器 categraf 推送地址写 nginx 的地址,nginx 直接 proxy_pass 到 n9e 的地址。
如果想了解我司的部署架构,可参考我之前的一篇总结文章:基于 n9e 的 Rancher 容器平台和主机混合服务架构监控方案 (opens new window)
- 3/ V6 提供了单独
alert和pushgw二进制包,用来做下沉式的单机房部署,可解决网络限制问题。
除了中心架构部署,还支持下沉式单机房部署:
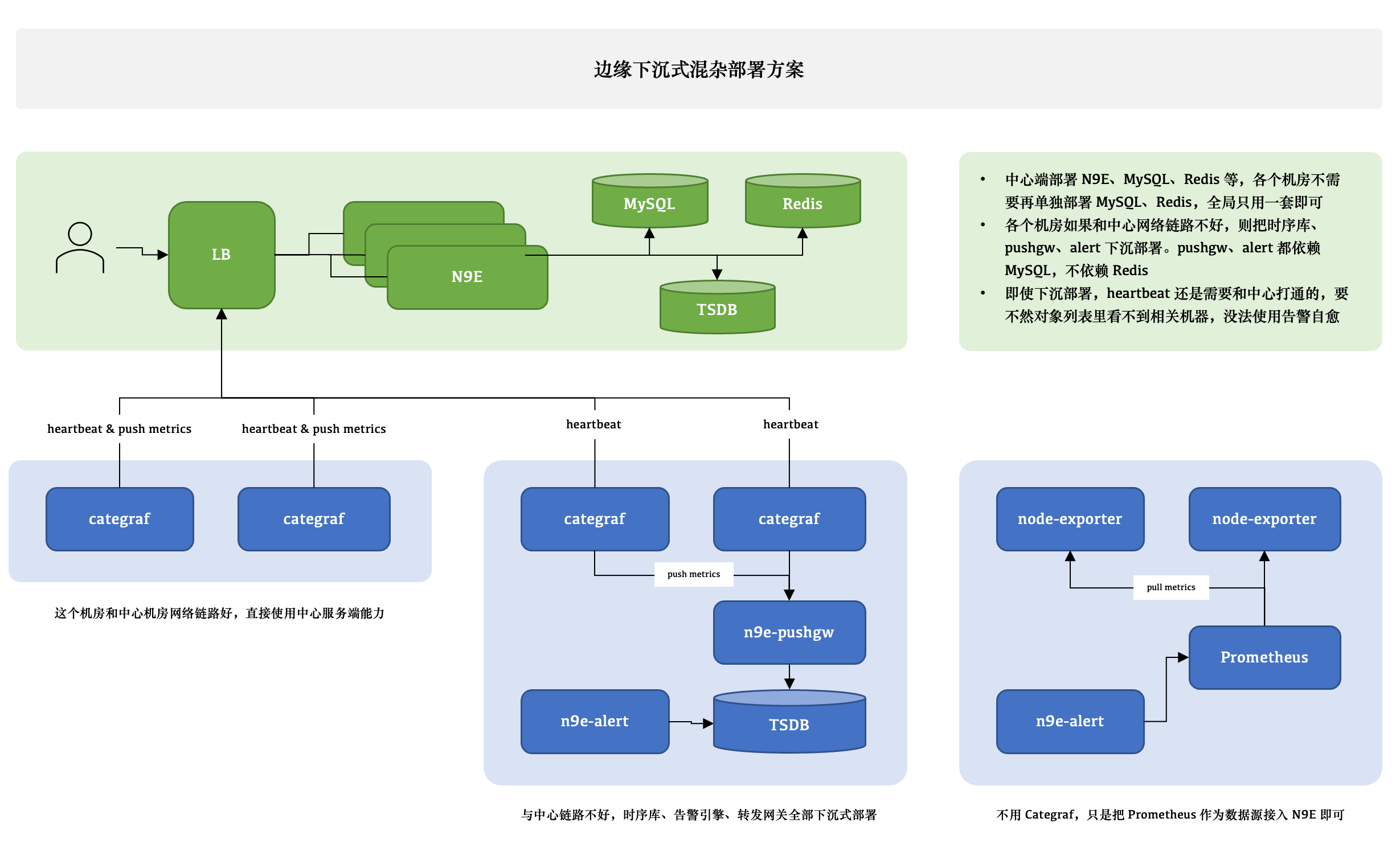
这种部署架构适用于机房到 n9e 集群网络不佳的情况,pushgw 用来识别机器的 ident 会存储 Mysql,alert 直接查询 TSDB 对数据做报警处理。
机房 TSDB 出图的话,需要配置为 n9e 集群的数据源。pushgw 和 alert 需要连接 n9e 集群的 Mysql,做数据上报和告警规则的读取。
- 4/ 使用 VM 时,单机版的 vm 官方数据最大可抗 100w/s ,这取决于机器自身的配置,目前试试过的机器最大有 80w/s,机器配置比较高。
单机版的 VM 相比集群,只有一个二进制文件,维护部署起来更加的方便,在不使用租户等高级功能时,单机版可能是更好的选择。官方文档描述单机版针对 CPU、内存、带宽及磁盘的 IO 做了优化 (opens new window),可通过垂直升配来解决性能问题。
VM 自身提供了 /metrics 接口,可通过 promethues 或 vmagent 来采集,也可启动时添加参数 --selfScrapeInterval=10s 实现自采集。
VM 的一些重要参数:
--storageDataPath指定数据存放位置;--selfScrapeInterval实现自采集;--retentionPeriod保留数据 N+1 个月;
更多优化参数,可参考官方文档: https://docs.victoriametrics.com
# 思考
单机 VM 性能虽然强劲,官方号称可以抗 100w/s 的写入,但是仍然存在一些问题。
- 1、单机风险问题。
针对单机 VM,官方也给出了高可用方案:副本双写 (opens new window)。在数据查询时,官方建议使用 Promxy (opens new window) 做代理,来聚合多个 VM 的数据,但是在它的文档中,我并没有看到“去重”的字眼,该方案需要进一步的验证。
目前我司的方案,使用 NFS 挂载机器,作为 VM 的存储目录,这样即使机器挂了,我们可以快速的在另一台机器上再起一个相同的 VM ,数据因为是挂载在 NFS 的所以并不会丢失。至于性能,我司流量目前在 2w/s 的写入量,目前并没有发现 NFS 的写入瓶颈。
- 2、单机 VM 还有自监控的问题,当它挂掉的时候,是没法利用 n9e 来报警的,只能借助其他报警方式。
如上分享给大家,可以作为一种参考方案。