DRAFT Kubernetes 学习笔记 - 监控系统
方案调研
目前容器化监控的几种方案:
Heapster 通过 cAdvisor 组件收集 Node 和 容器的监控数据;
kubernetes 1.13 彻底移除对 Heapster 的使用,Heapster 仓库也归档,不再更新维护。
- 基于 Prometheus 生态的监控方案;
Prometheus 在2016加入 CNCF ( Cloud Native Computing Foundation )。目前,业界容器化监控 Prometheus 已成为标准、首选。
基于 Prometheus,主要有以下两套方案:
- 在集群中手动部署 Prometheus 的各种组件 ;
- 采集项:
- node-exporter 采集node监控
- cAdvisor 容器级别的监控指标
- kube-state-metrics 采集pod相关监控指标
- 存储:
- 临时 prometheus
- 持久化 influxdb /VictorMetric
- 报警:
- alermanager
- n9e
- 采集项:
手动部署可参考文档:https://docs.prometheus.cool/Kubernetes/Prometheus-Statefulsets-1/
- kube-prometheus,基于CoreOS 之前发布的 Prometheus Operator 来实现部署维护;
该存储库收集了 Kubernetes 清单、Grafana仪表板和Prometheus 规则以及文档和脚本,以使用 Prometheus Operator提供易于操作的端到端 Kubernetes 集群监控与Prometheus。
部署可参考文档:http://gitlab.bokecc.com/opgroup/dev/cc_dev_docs/blob/master/dev/container/k8s_operator.md
k8s 官方 Operator 文档:https://kubernetes.io/zh/docs/concepts/extend-kubernetes/operator/
Operator Hub 文档:https://operatorhub.io/
Prometheus Operator 文档:https://prometheus-operator.dev/
Operator好处 因为是prometheus主动去拉取的,所以在k8s里pod因为调度的原因导致pod的ip会发生变化,人工不可能去维持,自动发现有基于DNS的,但是新增还是有点麻烦。
Prometheus-operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator这个controller有BRAC权限下去负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
在Kubernetes中我们使用Deployment、DamenSet、StatefulSet来管理应用Workload,使用Service、Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
而除了这些原生的Resource资源以外,Kubernetes还允许用户添加自己的自定义资源(Custom Resource)。并且通过实现自定义Controller来实现对Kubernetes的扩展,不需要用户去二开k8s也能达到给k8s添加功能和对象。
因为svc的负载均衡,所以在K8S里监控metrics基本最小单位都是一个svc背后的pod为target,所以prometheus-operator创建了对应的CRD: kind: ServiceMonitor ,创建的ServiceMonitor里声明需要监控选中的svc的label以及metrics的url路径的和namespaces即可
Prometheus 方案详解
数据采集
日常监控:
- 基础设置,cpu/mem/disk/net
- 业务信息,port/process/trace/link
- 自定义,特有指标
容器需要采集或监控的数据指标:
- 基础设施,服务器节点(node节点)
- k8s 基础组件健康情况
- k8s 整体资源的饱和度
- 自定义
采集方案如下:
- 基础设置
- node 主机信息 ---> node-exporter
- 各组件监控及资源使用情况、容器性能(如容器的CPU、内存、文件和网络的使用情况),cAdvisor ---> state-metrics
- 业务信息:
- 容器健康状态,Probes ---> state-metrics
- 健康探测(link/trace)---> 外部探测(自建、阿里云)
- 自定义,---> 自己暴露 metrics 接口
数据存储
Prometheus 作为收据收集和临时存储使用,因为单点不具备扩容能力,不适合做持久化存储。
持久化存储,目前业界有两种比较成熟的开源方案:
VictoriaMetric (只支持写,不支持读1)
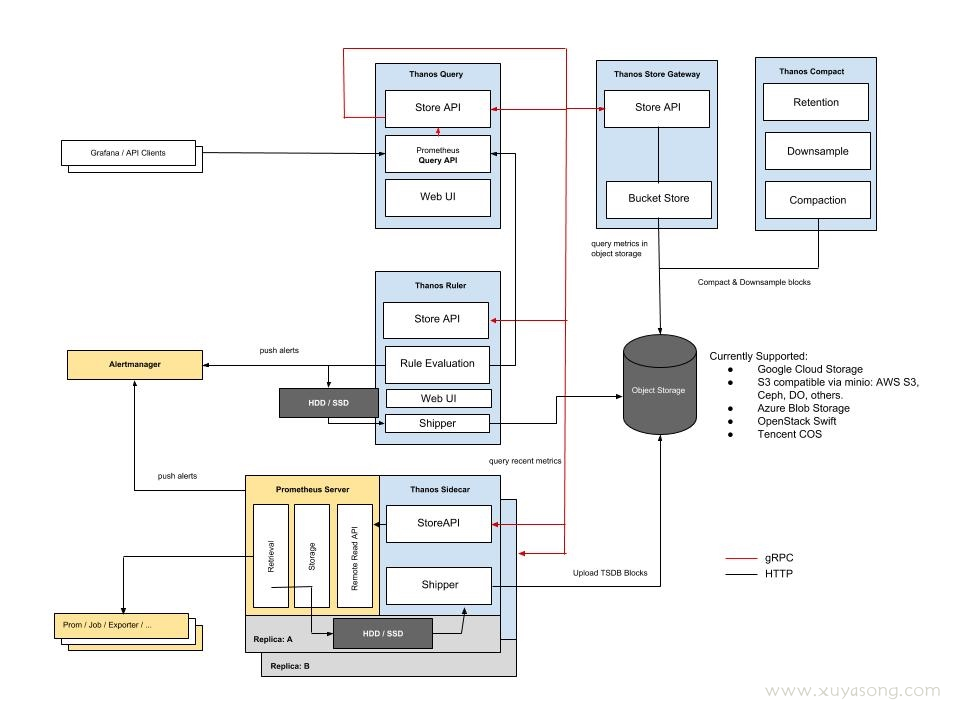
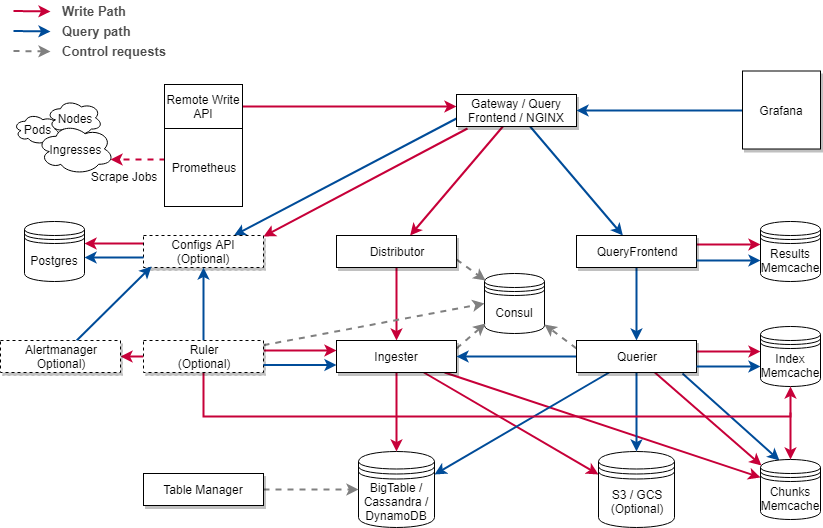
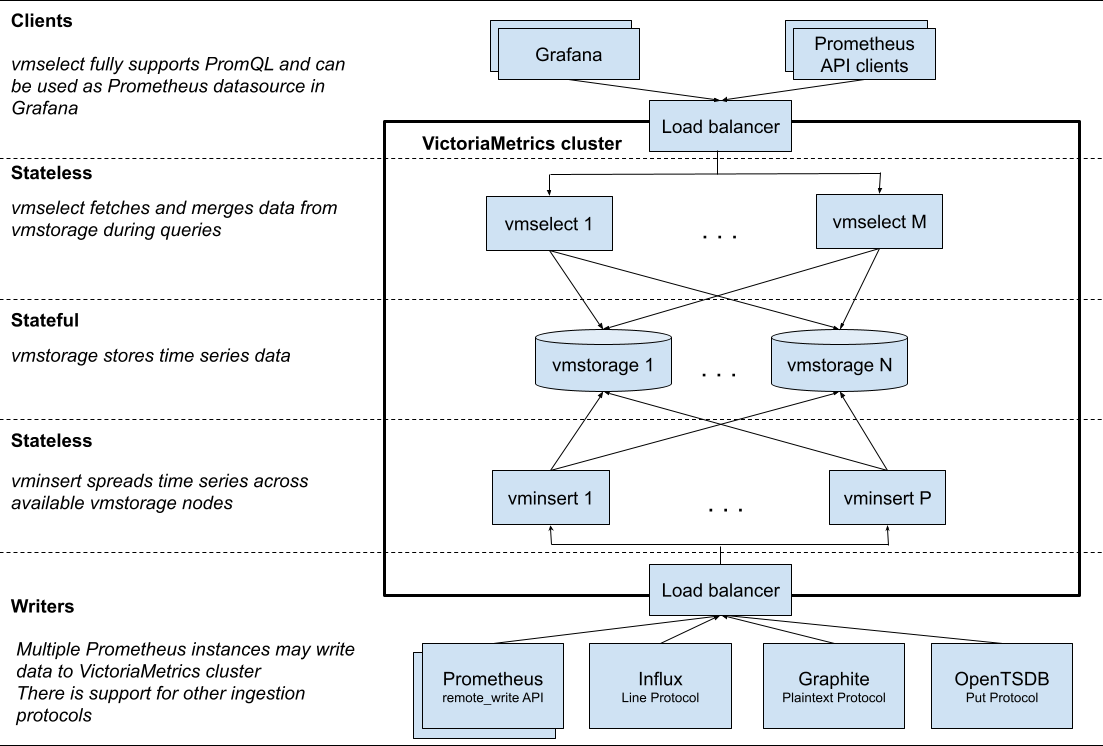
Thanos vs VictoriaMetric 两种方案对比,可参考文档: https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-thanos
Cortex vs VictoriaMetric: https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-cortex
总结如下:
架构上:vm 组件少,架构简单,不依赖第三方组件。Thanos 最少可部署三个基础组件Sidecar、Store[6] Gateway、Query,需要外部对象存储。Cortex 基础组件:Nginx/gateway、Distributor、Ingester、Query,依赖第三方组件如Consul、Memcache等。
数据高可用上:vm 通过 Prometheus RemoteApi 实时推送数据,只可能会丢失几秒钟的数据,Prometheus v2.8.0+ 会从WAL中同步数据,理论上不会丢失数据。 vm 和 cortex 都支持副本,保证集群节点有问题时,数据的可用性。Thanos 数据存储在对象存储,依赖对象存储的高可用性。
功能兼容性丰富度:都兼容Prometheus PromQL / 多租户等。除了 Prometheus remote_write 协议之外,还接受多种流行数据摄取协议中的数据 - InfluxDB、OpenTSDB、Graphite、CSV、JSON、本机二进制文件。
性能:vm 查询走本地磁盘相对高效,vmselect 聚合多节点副本,实现去重。Cortex 经过其他大厂生产验证, VM 查询性能 > Cortex 参考这里。Thanos 查询短时间的数据时,性能高,因为数据在Prometheus实例上,查询长时间的数据时,因为数据块在对象存储,受网络环境影响比较大。
报警
alertmanager
n9e
与现有监控结合
n9e
grafana
- admin账号密码配置: https://www.ancii.com/at6lje4j8/
- 直接 修改 helm 配置values 文件
部署高可用
多 Prometheus 副本,接后端 VictoriaMetric 聚合去重查询。
扩展阅读
https://prometheus-operator.dev/docs/prologue/introduction/
https://rancher.com/docs/rancher/v2.6/en/monitoring-alerting/
https://www.kubernetes.org.cn/2432.html
https://docs.prometheus.cool/
https://blog.csdn.net/weixin_33720452/article/details/91875529
thanos: http://www.xuyasong.com/?p=1925
victoria:
- https://blog.csdn.net/weixin_26711867/article/details/108971299
- https://medium.com/miro-engineering/prometheus-high-availability-and-fault-tolerance-strategy-long-term-storage-with-victoriametrics-82f6f3f0409e
thanos vs victoria : https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
victoriaMetric 存储机制:https://zhuanlan.zhihu.com/p/368912946