 夜莺 V6 之标签和自愈
夜莺 V6 之标签和自愈
本篇为夜莺黄埔营直播第二场之后的一些总结和思考,希望对大家有帮助。
夜莺黄埔营(如果感兴趣,可以搜索到他们的官网,加入 QQ 群,培训完全免费)第二场主要从夜莺的基本功能出发对夜莺的所有功能介绍了一遍,我看的回放,时间原因,直播老师讲解的比较快,我就自身的一些 V5 使用经验来和大家分享下吧。
# 标签
标签在 Prometheus 的数据生态中,可谓是非常重要的概念,主要使用它来标识和分类数据样本。可以通过不同的标签标识不同的样本,在查询和聚合时进行区分和过滤,使用非常灵活和方便。
夜莺时序数据源为遵循 Prometheus 相关协议的时序数据库,所以Prometheus上标签的特性和优点也继承了过来。
在使用 categraf 或 telegraf 等采集端采集的时候,各插件会给采集数据打上预先设置好的标签,例如:
# 磁盘使用情况
disk_used{device="obsfs", fstype="fuse.obsfs", ident="test1", mode="rw", path="/data"}
2
我们便可以根据标签 path 来配置具体报警监控的目录。
标签标记的好坏,直接影响到数据的可用性。下边是我司的一些使用方式,供大家参考:
针对机房、可用区标记专门的标签,可针对整个机房或可用区多模糊匹配来做监控或屏蔽。如:
region=shanghaiaz=d;针对产品线、服务池标记专门的标签,可针对产品线或服务应用集群做监控或屏蔽。如:
bg=产品线1service=seervice1;其他特殊用途,需要分组的情况。
打上上述标签后,我们的数据可能是这样的:
disk_used{device="obsfs", fstype="fuse.obsfs", ident="test1", ip="192.168.1.5", mode="rw", path="/data", bg="产品线1", serivce="service1", region="shanghai", az="d"}
通过 V5 版本的使用,在整个数据采集的链路中,可以给数据打标签的地方主要有下边几点:
采集agent,categraf 和telegraf 都支持在采集数据时,添加全局的自定义的标签。上边数据的ip,便是我们这里打上的。对象列表中,标记自定义标签,这里的标记是针对对象所有采集数据的。和agent 的全局tag,相同的效果。监控规则标签,该标签是用来区分监控规则的,不会标记到时序数据上,但是当我们来看报警时,报警数据的标签是会附带着这条tag标签的。
上边是针对标签的一些使用配置心得。
# 自愈
夜莺中的自愈,依赖外部命令执行通道 Ibex (opens new window) 服务。Ibex 分为server 端和agent 端,agent 周期性调用 server 的 rpc 接口,查询自己需要执行的任务脚本来执行。最新的 categraf 已经集成了 ibex 的agent 模块,可用直接启用。
在新资源部署时,直接部署categraf并启用 ibex 便可使用。但是,在存量的资源节点中,各公司都可能会有自己的命令行下发通道,比如 ansible 、saltstack 等。重复的部署命令行下发通道,不仅增加了维护成本,占用机器资源,还可能会有安全风险。
分享下我司的一个部署架构,利用 ansible 来充当命令执行通道:
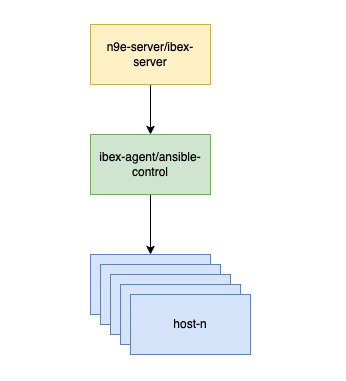
ibex-agent 只部署ansible的控制端节点就好了,无需全部部署启用。整个自愈控制流程是这样的,当有报警触发时,会回调 ibex-server 接口创建任务,ibex-agent 定制查询到自己处理的任务时,执行脚本,脚本中会编写ansible的执行命令。中间多了一个中转脚本,但是不需要所有节点部署ibex-agent。
#!/bin/bash
# e.g.
# export PATH=/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:~/bin
# ss -tln
echo 'test1' > ansible_hosts
ansible -i ansible_hosts test1 -m shell -a "echo '' > /opt/backend/logs/nginx/access.log"
2
3
4
5
6
7
8
9
10
上边是一个中转脚本,简单操作可直接通过 ansible 命令来实现,复杂的可再次通过 ansible script模块去执行复杂的脚本来实现。
# 思考
自愈这块,就像夜莺官网说的:
所谓的告警自愈,典型手段是在告警触发时自动回调某个 webhook 地址,在这个 webhook 里写告警自愈的逻辑,夜莺默认支持这种方式。另外,夜莺还可以更进一步,配合 ibex 这个模块,在告警触发的时候,自动去告警的机器执行某个脚本,这种机制可以大幅简化构建运维自愈链路的工作量,毕竟,不是所有的运维人员都擅长写 http server,但所有的运维人员,都擅长写脚本。这种方式是典型的物理机时代的产物,希望各位朋友用不到这个工具(说明贵司的IT技术已经走得非常靠前了)。
这中方式是比较简单的好实现的,但是它又是不够严谨的,服务的自愈是需要经过严格的论证分析的,并非简单的执行一个脚本。
当然,ibex 这种自愈方式已经可以帮我们解决很多运维工作的琐碎问题。
以上为今天的分享,欢迎留言交流。