「译」机器学习简介
本文为「资源分享计划第一期 0427」中分享的文章「Introduction To Machine Learning | Machine Learning Basics」的一个节选译文,主要介绍了机器学习的一些相关概念和机器学习的过程,大家可以通过本文了解如下信息:
- 为什么要机器学习
- 机器学习解决问题的类型
- 机器学习的分类
- 机器学习一个完整过程是什么样的
下面是原文 >>>
毫无疑问,机器学习是当今市场上最受欢迎的技术。其应用范围从自动驾驶汽车到预测ALS等致命疾病。机器学习技能的高需求是这个博客背后的动机。在这篇关于机器学习简介的博客中,您将通过使用R语言了解机器学习的所有基本概念和机器学习的实际实现。
为什么需要机器学习
自技术革命以来,我们一直在产生大量的数据。根据研究,我们每天产生大约2.5亿个字节的数据!据估计,到2020年,每个人每秒钟将创造1.7MB的数据。通过提供如此多的数据,最终可以构建预测模型,可以研究和分析复杂数据,以找到有用的见解并提供更准确的结果。Netflix和亚马逊等顶级公司通过使用大量数据来构建此类机器学习模型,以便识别可盈利的机会和避免不必要的风险。
以下是机器学习如此重要的原因:
- 数据生成的增加:由于数据的过度生成,我们需要一种可用于构建,分析和从数据中获取有用见解的方法。这就是机器学习的用武之地。它使用数据来解决问题并找到组织面临的最复杂任务的解决方案。
- 改进决策:通过使用各种算法,机器学习可用于做出更好的业务决策。例如,机器学习用于预测销售额,预测股票市场的下跌,识别风险和异常等。
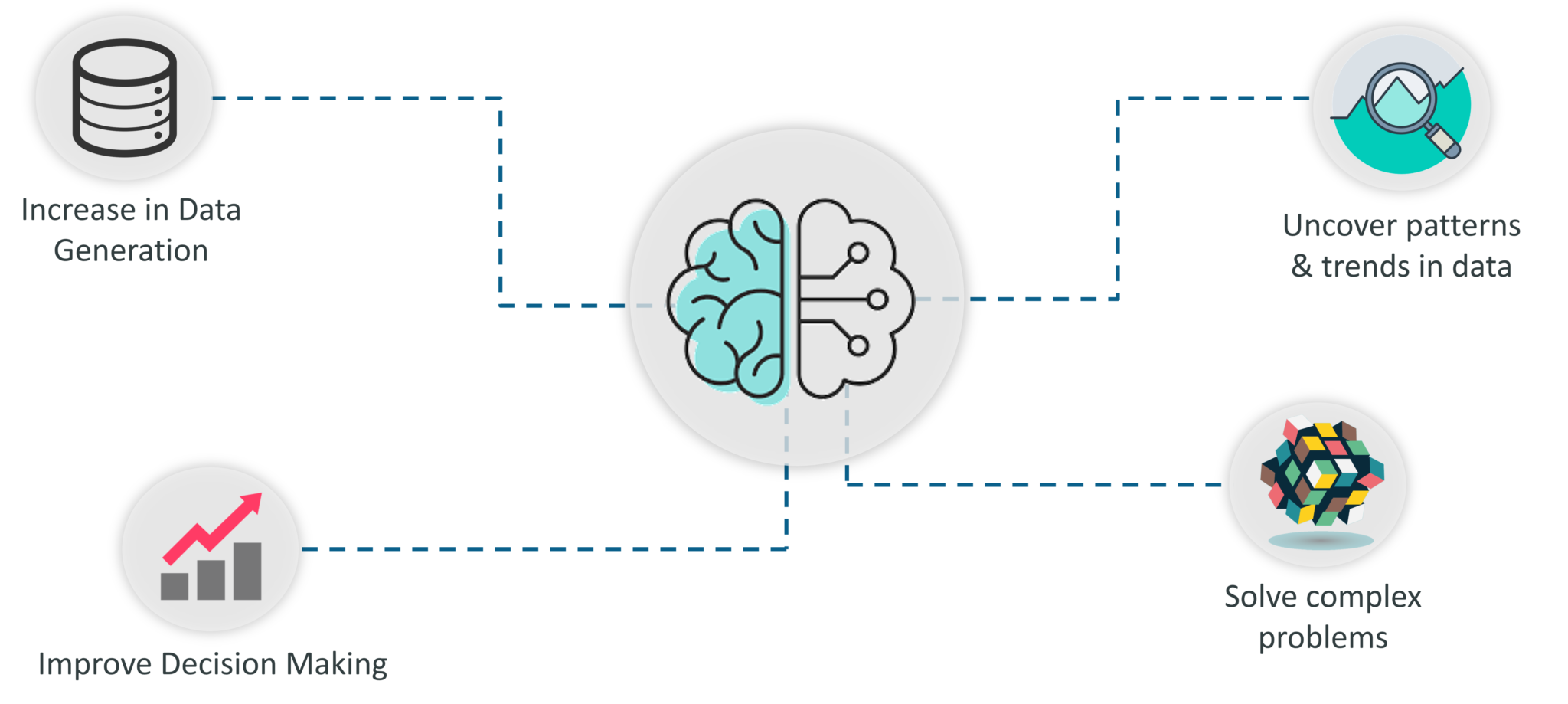
揭示数据的模式和趋势:查找隐藏模式并从数据中提取关键见解是机器学习中最重要的部分。通过构建预测模型和使用统计技术,机器学习允许您在透过表面挖掘深层次的更微小的数据价值。手动了解数据和提取模式需要数天时间,而机器学习算法可以在不到一秒的时间内执行此类计算。
解决复杂问题:从检测与致命ALS疾病相关的基因到建立自动驾驶汽车,机器学习可用于解决最复杂的问题。
为了让您更好地了解机器学习的重要性,让我们列出几个机器学习应用程序:
- Netflix的推荐引擎:Netflix的核心是臭名昭着的推荐引擎。Netflix推荐超过75%的观看内容,这些建议是通过实施机器学习来实现的。
- Facebook的自动标记功能: Facebook的DeepMind面部验证系统背后的逻辑是机器学习和神经网络。DeepMind会研究图像中的面部特征,以标记您的朋友和家人。
- 亚马逊的Alexa:臭名昭着的Alexa,基于自然语言处理和机器学习是一个高级虚拟助手,它不仅仅是播放你的播放列表中的歌曲。它可以预订优步,与家中的其他物联网设备连接,跟踪您的健康状况等。
- 谷歌的垃圾邮件过滤器: Gmail利用机器学习来过滤掉垃圾邮件。它使用机器学习算法和自然语言处理来实时分析电子邮件,并将其分类为垃圾邮件或非垃圾邮件。
这些是关于机器学习如何在顶级公司中实施的几个例子。这是关于机器学习十大应用程序的博客,可以阅读它了解更多信息。
现在您已经知道为什么机器学习如此重要,让我们来看看机器学习到底是什么。
机器学习简介
“机器学习”一词最早是由Arthur Samuel在1959年创造的。回顾一下,那一年在技术进步方面可能是最重要的。如果您通过网络浏览“什么是机器学习”,您将获得至少100个不同的定义。然而,Tom M. Mitchell给出了第一个正式定义:
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”
简单来说,机器学习是人工智能(AI)的一个子集,它使机器能够自动学习并从经验中进行改进而无需明确编程。从某种意义上说,这是让机器通过获得思考能力来解决问题的方法。
但等等,机器可以思考或做出决定吗?是这样的,如果您为机器提供大量数据,它将学习如何使用机器学习算法解释,处理和分析这些数据,以解决实际问题。
在进一步讨论之前,让我们讨论一下机器学习中最常用的术语。
机器学习定义
算法(Algorithm):机器学习算法是一组规则和统计技术,用于从数据中学习模型并从中获取重要信息。这是机器学习模型背后的逻辑。机器学习算法的一个例子是线性回归算法。
模型(Model):模型是机器学习的主要组成部分。通过使用机器学习算法训练模型。算法根据给定的输入映射模型应该采取的所有决策,以获得正确的输出。
预测变量(Predictor Variable):它是可用于预测输出的数据特征。
响应变量/反应变量(Response Variable):需要使用预测变量预测要素或输出变量。
训练数据(Training Data):机器学习模型使用训练数据构建。训练数据有助于模型识别预测输出所必需的关键趋势和模式。
测试数据(Testing Data):在训练模型之后,必须对其进行测试以评估其预测结果的准确程度。这是由测试数据集完成的。
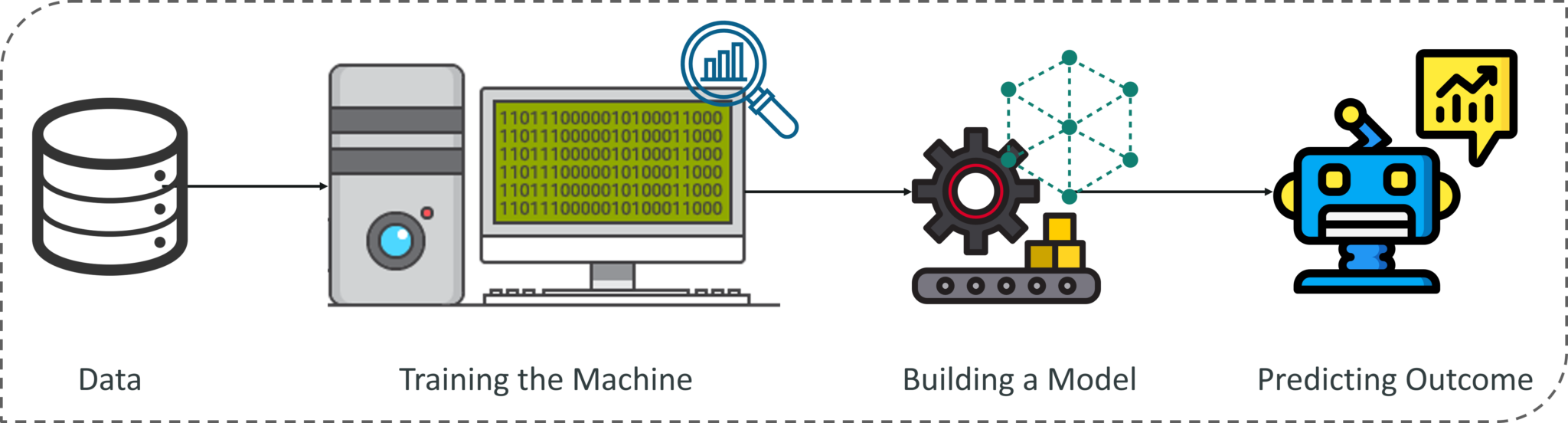
总结一下,看看上图。机器学习过程首先为机器提供大量数据,通过使用这些数据,机器经过训练,可以检测隐藏的决策和趋势。然后使用这些决策通过使用算法来构建机器学习模型以解决问题。
下面我们来看下机器学习过程。
机器学习过程
机器学习过程涉及构建可用于查找问题解决方案的预测模型。要了解机器学习过程,我们假设您已经遇到了需要使用机器学习解决的问题。
这个问题是:使用机器学习预测当地的降雨情况。
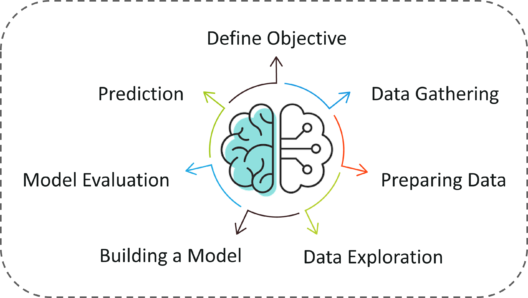
在机器学习过程中遵循以下步骤:
第1步: 定义问题陈述的目标(Define the objective of the Problem Statement)
在这一步,我们必须了解究竟需要预测的是什么。在我们的例子中,目标是通过研究天气条件来预测降雨的可能性。在此阶段,还必须记下解决此问题所需要的数据,或者需要遵循的方法类型。
第2步: 数据收集(Data Gathering)
在这个阶段,你必须提出如下的问题,
- 需要什么样的数据才能解决这个问题?
- 数据是否可用?
- 我怎样才能获得数据?
了解所需的数据类型后,您必须了解如何获取此数据。数据收集可以手动完成,也可以通过网络抓取完成。但是,如果您是初学者并且只是想学习机器学习,则不必担心获取数据。网上有1000多种数据资源,您只需下载数据集即可开始使用。
回到手头的问题,天气预报所需的数据包括湿度,温度,压力,地点,是否住在山区等措施。必须收集和存储这些数据进行分析。
第3步: 数据准备(Data Preparation)
您收集的数据格式会各异,您将在数据收集的过程中遇到许多不一致性,例如缺失值,冗余变量,重复值等。消除此类不一致性非常重要,因为它们可能会导致错误的计算和预测。因此,在此阶段,您扫描数据集是否存在任何不一致,并修复它们。
第4步: 探索性数据分析(Exploratory Data Analysis)
抓住这个阶段,因为这个阶段就是深入挖掘数据并找到所有隐藏的数据之谜。EDA或探索性数据分析是机器学习的头脑风暴阶段。数据探索涉及了解数据的模式和趋势。在此阶段,绘制所有有用的见解并理解变量之间的相关性。
例如,在预测降雨的情况下,我们知道如果温度降低,很可能会下雨。在此阶段必须理解和映射这种相关性。
第5步: 构建机器学习模型(Building a Machine Learning Model)
数据探索期间获得的所有见解和模式都用于构建机器学习模型。此阶段始终首先将数据集拆分为两部分,即训练数据和测试数据。培训数据将用于构建和分析模型。该模型的逻辑基于正在实施的机器学习算法。
在预测降雨量的情况下,由于输出将为True(如果明天会下雨)或False(明天不下雨),我们可以使用Logistic回归等分类算法。
选择正确的算法取决于您尝试解决的问题类型,数据集以及问题的复杂程度。在接下来的部分中,我们将讨论使用机器学习可以解决的不同类型的问题。
第6步: 模型评估和优化(Model Evaluation & Optimization)
在使用训练数据集构建模型之后,最后是时候将模型进行测试了。测试数据集用于检查模型的效率以及预测结果的准确程度。一旦计算出准确度,就可以在此阶段实施模型的任何进一步改进。参数调整和交叉验证等方法可用于提高模型的性能。
第7步: 预测(Predictions)
一旦模型被评估和改进,它最终用于进行预测。最终输出可以是分类变量(例如,真或假),或者它可以是连续数量(例如,股票的预测值)。
在我们的例子中,为了预测降雨的发生,输出将是一个分类变量。
这就是整个机器学习过程。
机器学习类型
机器可以通过遵循以下三种方法中的任何一种来学习解决问题。这些是机器可以学习的方式:
- 1、监督学习
- 2、无监督学习
- 3、强化学习
监督学习(Supervised Learning)
监督学习是一种使用标记良好的数据教授或训练机器的技术。
要理解监督学习,我们可以考虑一个类比。作为孩子,我们都需要指导来解决数学问题。我们的老师帮助我们了解了什么是添加以及如何完成。同样,您可以将监督学习视为一种涉及指南的机器学习。标记的数据集是教师,它将训练您理解数据中的模式。标记数据(labeled data)集只是训练数据集。
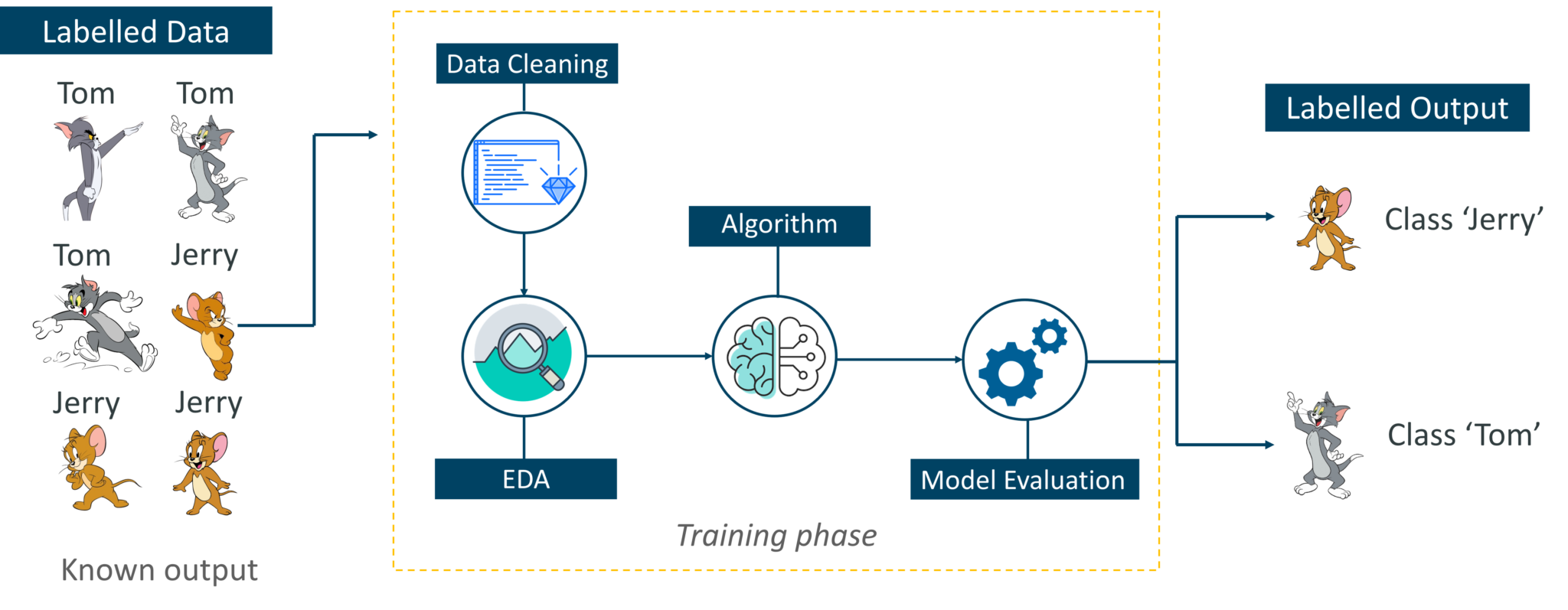
考虑上图。在这里,我们正在为Tom和Jerry提供机器图像,目标是让机器识别图像并将图像分为两组(Tom图像和Jerry图像)。提供给模型的训练数据集被标记,就像我们告诉机器一样,“这就是汤姆的样子,这就是杰瑞”。通过这样做,您将使用标记数据训练机器。在监督学习中,在标记数据的帮助下完成了明确的训练阶段。
无监督学习(Unsupervised Learning)
无监督学习涉及使用未标记数据进行培训,并允许模型在没有指导的情况下对该信息采取行动。
把无监督学习想象成一个没有任何指导就能学会的聪明孩子。在这种类型的机器学习中,模型没有标记数据,因为在模型中不知道“这个图像是汤姆而且这是杰瑞”,它通过它自己计算出模式以及汤姆和杰瑞之间的差异。
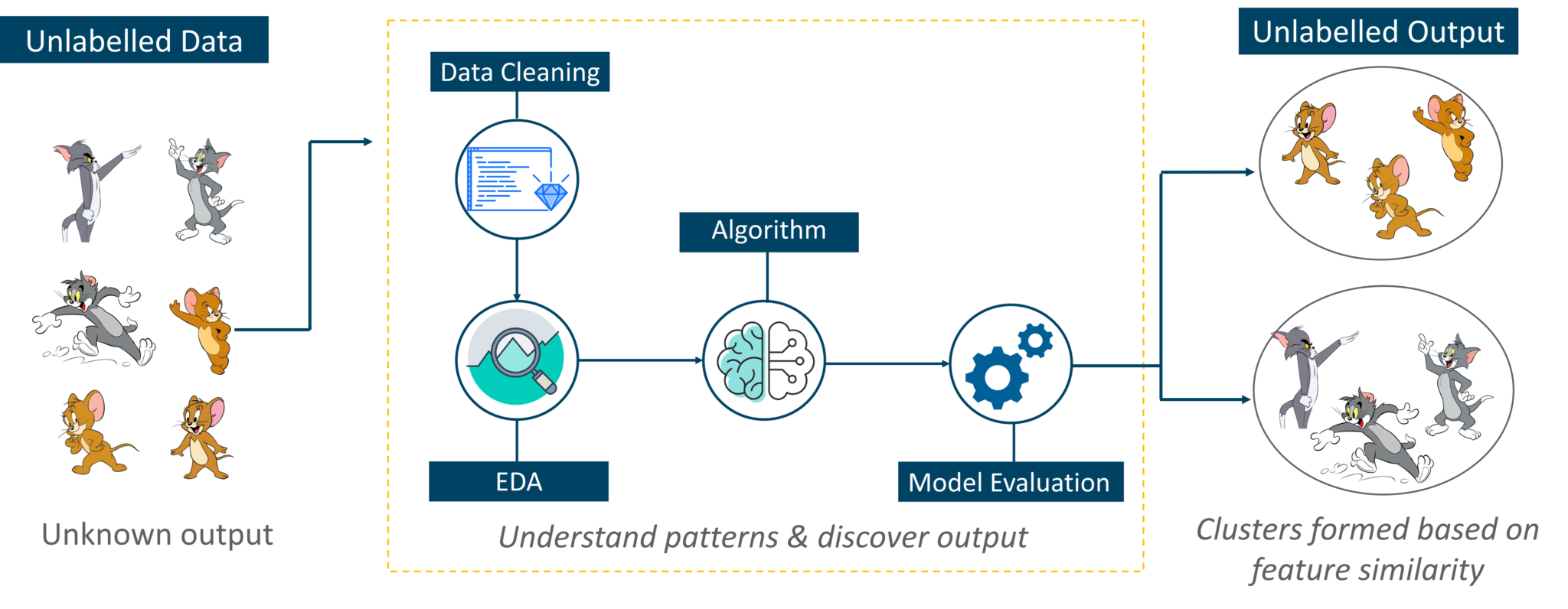
例如,它识别Tom的突出特征,例如尖耳朵,更大的尺寸等,以理解该图像是类型1.类似地,它在Jerry中找到这样的特征并且知道该图像是类型2.因此,它将图像分为两个不同的类,而不知道Tom是谁还是Jerry。
强化学习(Reinforcement Learning)
强化学习是机器学习的一部分,其中代理被放置在一个环境中,并且他通过执行某些操作并观察从这些操作获得的奖励来学习在这种环境中 行为。
这种类型的机器学习是相对不同的。想象一下,你被困在一个孤岛上!你会怎么做?
恐慌?是的,当然,最初我们都愿意。但随着时间的推移,你将学习如何在岛上生活。您将探索环境,了解气候条件,在那里生长的食物类型,岛屿的危险等。这正是强化学习的工作原理,它涉及一个代理人(你,被困在岛上)在一个未知的环境(岛屿)中,他必须通过观察和执行导致奖励的行动来学习。
强化学习主要用于高级机器学习领域,如自动驾驶汽车,AplhaGo等。
这总结了机器学习的类型。现在,让我们看一下使用机器学习解决的问题类型。
机器学习中的问题类型
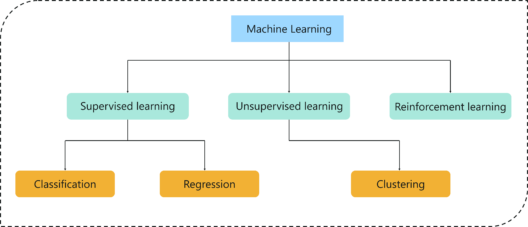
考虑上图,机器学习中可以解决三种主要类型的问题:
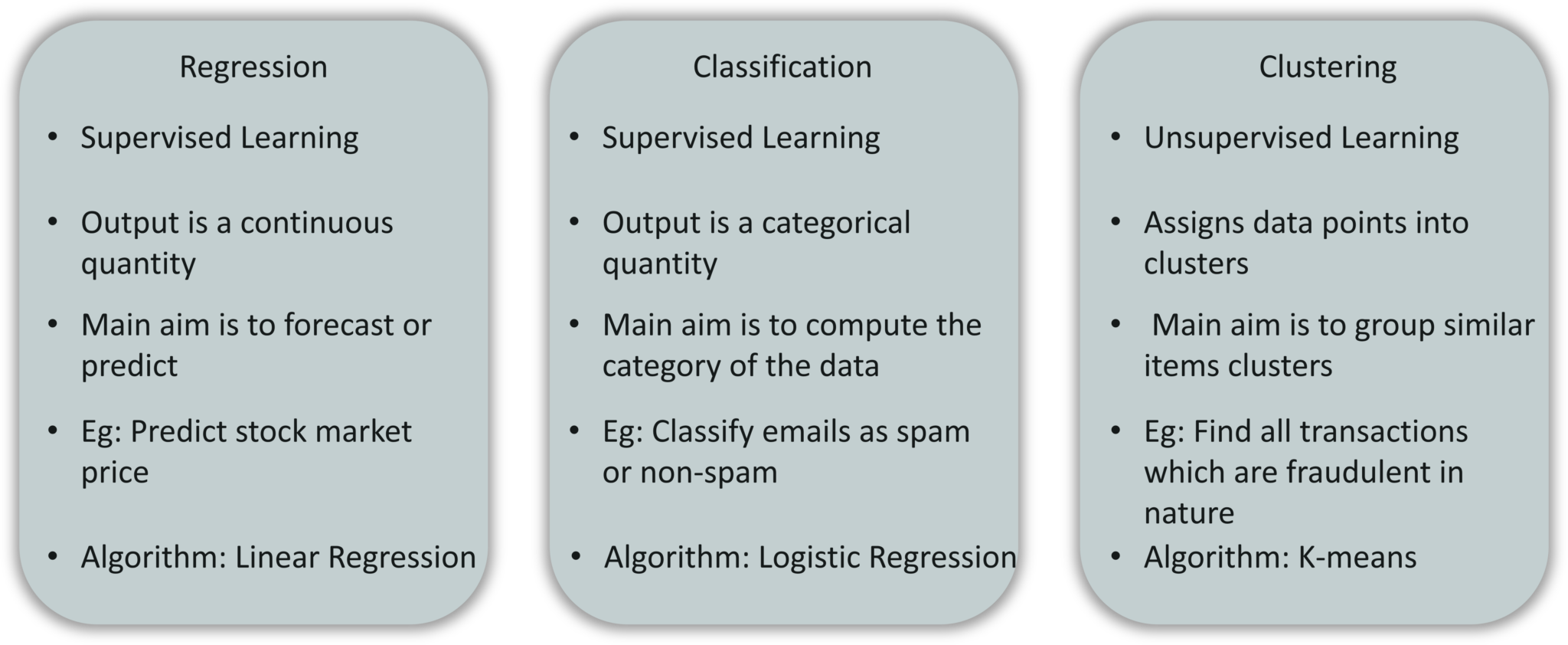
1、回归(Regression):在这种类型的问题中,输出是连续的数量。因此,例如,如果您想要根据距离预测汽车的速度,那么这是一个回归问题。回归问题可以通过使用线性回归等监督学习算法来解决。
2、分类(Classification):在此类型中,输出是分类值。将电子邮件分为两类,垃圾邮件和非垃圾邮件是一种分类问题,可以通过使用监督学习分类算法来解决,例如支持向量机,朴素贝叶斯,Logistic回归,K最近邻等。
3、聚类(Clustering):此类问题涉及基于特征相似性将输入分配到两个或更多个聚类中。例如,可以通过使用诸如K-Means聚类之类的无监督学习算法将观众根据他们的兴趣,年龄,地理等聚类成类似的组。
这是一个总结回归,分类和聚类之间差异的表。