基于n9e的 Rancher容器平台和主机混合服务架构监控方案
在讲方案之前,先说下应用场景。
目前我司有部分云厂商的云服务器且是不同厂商,也有托管机房的物理设备,笼统来说这已经算是一个混合云的场景了。我们服务部署有直接在云服务器部署的,也有在容器平台Rancher,各服务之间尽量做到了不跨厂商机房交互,业务逻辑上各机房互为备份,有些必要的交互,没专线只能走公网,做了ip和防火墙的限制。
针对这种简易混合云的业务场景,如何做基础和业务监控呢?下面我来简单说下我们的方案,希望可以抛砖引玉,共同交流。
整体架构
一直比较中意 Prometheus 的指标+标签的数据存储和查询方式,想把主机的监控数据加入进去,但是需要部署 exporter、docker,增加了好多组件。如果自己收集又需要一个数据转换的网关式的服务,极为不便。
之前有在关注夜莺,V4.0+ 加入了 Prometheus 的数据源,但是整体使用和组件部署还是偏繁琐。V5 版本的发布,如获至宝,非常契合我们的需求场景。我们的混合云监控,便是围绕 夜莺v5 构建的。整体架构图如下:
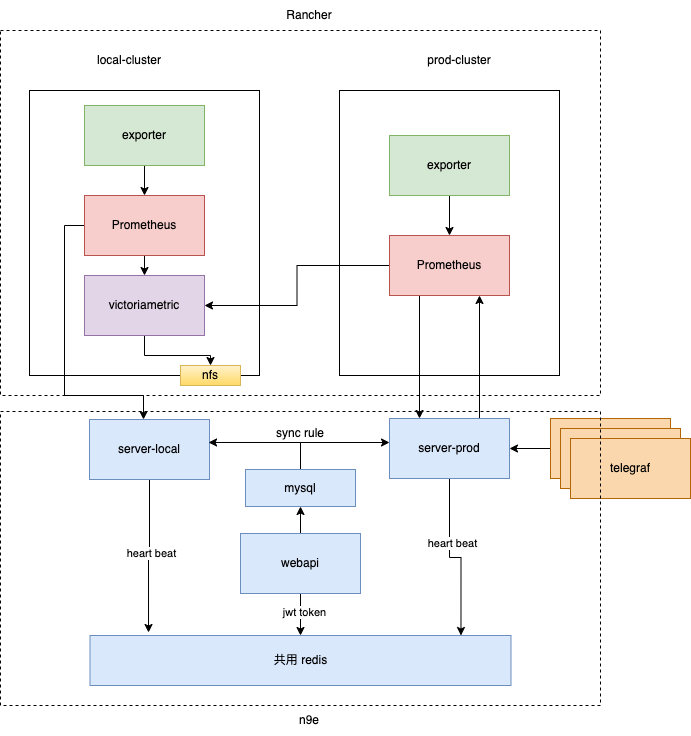
简要说明:
- local-cluster/prod-cluster: 两个 Rancher 生态的 K3S 集群;
- Prometheus: 其中有两个 Prometheus 集群,分别收集所属集群的容器平台相关监控;
- VictoriaMetric: 集群部署在 local 集群,和业务数据分离,避免负载相互影响;
- server-local: n9e server 负责针对 local 集群的报警规则配置、报警、数据查询等;
- server-prod: n9e server 负责针对 prod 集群的报警规则配置、报警、数据查询、主机监控上报等;
- webapi: n9e webapi 前端页面,主要功能规则配置(报警和故障自愈)、数据查询、告警查看、业务权限隔离等;
下边我分别从监控的几个重要组件说下我们的选型和思考。
采集器
业界有很多采集器,我司需要采集的场景主要分两种,容器和主机,针对容器我们采用 Prometheus 生态的各种 exporter,针对主机我们采用了夜莺团队推荐的 telegraf(后来夜莺团队开发了自己的categraf),telegraf 各种采集也是插件化的,生态异常丰富,基本覆盖了cpu、内存、disk、process等基础监控和各种中间件监控。除了自带的核心插件外,我们可以编写自己的采集逻辑,通过telegraf 的 exec 插件来实现自定义采集。
容器这块的采集器Prometheus生态已成为一种事实上的标准。主机采集这块选择 telegraf 主要是基于如下几点:
- telegraf 二进制文件,无依赖库,占用资源相对小;
- go开发,契合团队技术栈,有问题可二次开发;
- 丰富的插件,可自定义插件,这样我们可以把之前很多 openfalcon 的插件移植过来;
后期夜莺团队开源的 categraf,很好的继承了 telegraf 的以上有点,并做了大量的优化,推荐试用。
针对采集上报数据的整个链路,n9e-server 起到了 push-gateway 的作用,让整体架构具有了 push 的模型能力。使整体的上报功能更丰富,适应场景更广。
存储
存储这块,PromQL 类的存储和查询是我们想要的,Prometheus 又是容器这块的标配,我们围绕 Promethues 做了高可用持久化方案的调研,针对目前比较流行的 Thanos 架构、Cortex 架构、VictoriaMetric 架构进行了对比,最终选用了 VictoriaMetric。具体的对比总结可看我之前的文章 k3s 监控方案调研
VictoriaMetric 的选用主要基于以下几点:
- 组件架构建链,不依赖第三方组件,部署维护简单方便;
- 完全兼容 PromQL 语法,增加了自己特有的语法;
- 夜莺系统的完全兼容;
报警
报警这块应该是我们使用夜莺的另一大动力,它完全可以替代 Prometheus 生态的 Alertmanager, 将各种 Rule 直接存储在数据库,理解和配置更加方便。 最新版本,夜莺使用 go 重新了之前的报警脚本,内置了邮件、钉钉、企业微信的报警通道。同时保留了之前报警脚本的功能,以支持脚本的自定义。整体来说完全满足需求,特殊需求完全可自己定制。
总结
基于夜莺的这套系统部署,完美的满足了我司容器和主机场景下的混合云监控。